Dự kiến hệ thống KRX sẽ go-live chính thức vào tháng 5 tới
· 2 min read
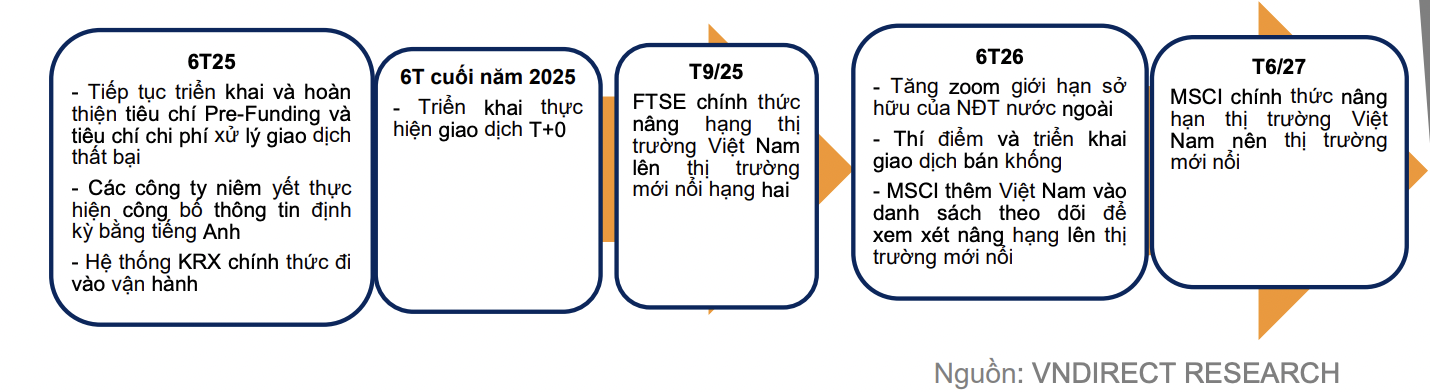
Theo báo Nhân Dân, hệ thống KRX dự kiến sẽ chính thức go-live vào tháng 5 năm nay. Đây là một trong những bước tiến quan trọng nhằm hiện đại hóa thị trường chứng khoán Việt Nam, nâng cao hiệu suất giao dịch và tăng cường khả năng kết nối với thị trường quốc tế.
Những điểm nổi bật của hệ thống KRX:
- Tăng tốc độ xử lý giao dịch, giúp giảm thời gian chờ và nâng cao trải nghiệm của nhà đầu tư.
- Cung cấp các sản phẩm mới, bao gồm giao dịch T+0 và các công cụ phái sinh nâng cao.
- Nâng cao năng lực giám sát thị trường, đảm bảo minh bạch và công bằng hơn trong giao dịch chứng khoán.
- Tích hợp công nghệ tiên tiến, hỗ trợ các chuẩn mực giao dịch hiện đại.
Hệ thống KRX đã được chuẩn bị trong nhiều năm và hiện đang trong giai đoạn thử nghiệm cuối cùng trước khi triển khai chính thức. Việc hệ thống mới đi vào hoạt động sẽ đánh dấu một cột mốc quan trọng trong quá trình chuyển đổi số của thị trường chứng khoán Việt Nam.
🔗 Xem chi tiết bài viết gốc:
Nhân Dân